vSphere 5.1 and VMs Inaccessible After NAS downtime
Tonight my home-built Nexenta-VM decided to reboot itself during my nightly backup cycle. Not too nice, but it recovered without too much hassle by itself. Even though the NFS shares were available again, my vSphere 5.1 environment now has a pretty large number of VMs that have become grayed out (Inaccessible), even though they are still accessible on the NAS shares. Easily solved, if you know how…
What it looks like
We start with an email I found in my Inbox, stating that my Nexenta-VM had a problem and was rebooted at 1:26AM. After the reboot all the shares became available again, but my vSphere environment was left in a mess:

vCenter showing inaccessible VMs after a short NAS failure
As you can see a lot of VMs are inaccesible. Actually only VMs that were powered off at the time show up greyed out; all VMs that were running during the NAS failure have been hanging, but they resumed properly after the NAS came back online. In the example above I actually already fixed some of the VMs; originally ALL powered-off VMs were in the “inaccessible” state!
Proof that they are not inaccessible
First off I browsed to one of the inaccesible VMs on the NAS datastore, and found that all seemed well:
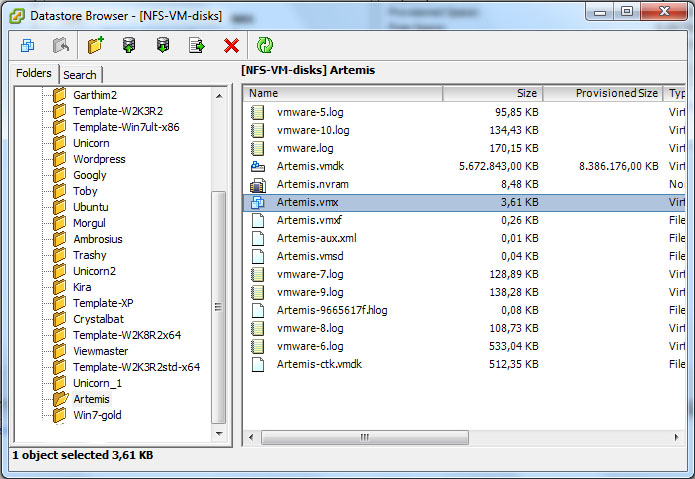
Even though the vSphere 5.0 node claimed the VM was “Inaccessible”, all seems well at the datastore level…
I tried to get some VMs back the “hard” way:
- Remove the VM from inventory;
- Browse for the VM on the NAS datastore;
- Register the VM again using the *.vmx file.
This approach does actually work, but it leaves you with a “new VM that is an old one”. So VMware View… Won’t get it. Your backup appliance… Won’t get it. It just takes more fixing than you might anticipate. So I came up with a way simpler approach…
Fixing it the easy way
I figured I needed to somehow tell vSphere that the inaccessible VM was actually no longer inaccessible, and force it to reload the configuration. And vimsh can do exactly that… It has the ability to reload a VM into a host, and exactly that does the trick!
First, we need to access the host using ssh or the direct commandline as root. From there, you can simply find all VMs that are inaccessible using the following command:
vim-cmd vmsvc/getallvms >grep skip
As an example, this will generate output like this:
~ #
~ # vim-cmd vmsvc/getallvms >grep skip
Skipping invalid VM '118'
Skipping invalid VM '127'
Skipping invalid VM '147'
Skipping invalid VM '16'
Skipping invalid VM '184'
Skipping invalid VM '185'
Skipping invalid VM '190'
Skipping invalid VM '25'
Skipping invalid VM '92'
Skipping invalid VM '94'
Skipping invalid VM '95'
Skipping invalid VM '97'
These are actually all the VMs that are inaccessible on this host right now. Now it is easily fixed, by simply calling a reload for each “skipped” VM using this command:
vim-cmd vmsvc/reload [NUMBER]
This will trigger reload actions on the host:

Reloading the entities as a result from reload commands and presto! The VM is accessible again.
So simply repeat the reload command for all the “skipped” VMs and your problem is solved. Should be easy to script in Powershell as well.
NOTE: The numbering between the VI client and vimsh actually DO NOT MATCH (see example above). So make sure you use vimsh to find the numbers of the inaccessible VMs, and not use the VI client for this!
To my understanding this is a known issue: VMware plans to fix this in vSphere 5.1 update1. In the mean time, use the reload described here and avoid removing and re-adding your VMs.


 LinkedIn
LinkedIn Twitter
Twitter
I had the same thing.
I fixed it even more easy. just login with ssh to your ESXi host.
execute services.sh restart
everything should be fine after one or two minutes. disconnecting the ESXi host and reconnecting seems to work also.
This is also fixable with powershell. See:
http://blog.mattvogt.net/2013/02/08/vms-grayed-out-after-nfs-datastore-restored/
[…] Source: http://vmdamentals.com/?p=4503 […]